
# 메세지 큐란?
메시지 지향 미들웨어(Message Oriented Middleware)은 독립된 서비스간에 데이터를 주고받을 수 있는 형태의 미들웨어, 분산되어 있는 시스템간의 Connector 역할을 통해 결합성을 낮추고, 실시간으로 비동기식 데이터를 교환할 수 있도록 하는 소프트웨어입니다.
MOM중에는 메세지 큐가 존재하며 이는 프로세스 또는 프로그램 간에 데이터를 교환할 때 사용하는 통신 방법 중에 하나입니다. 서버간 데이터를 주고받을때는 시스템 장애를 항상 고려해야하는데 이때 메세지 큐가 중요한 역할을 해줍니다.
메시지 큐 브로커(message queue broker)는 메시징 시스템 내에서 메시지의 생성자(프로듀서)와 소비자(컨슈머) 사이에서 메시지를 관리하고 전달하는 중간 역할을 하는 서비스나 어플리케이션을 의미하는데 크게 메세지 브로커(RabbitMQ), 이벤트 브로커(Kafka)가 존재합니다.
- 메세지 브로커
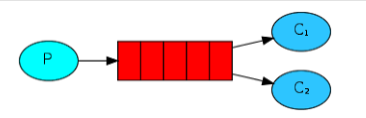
publisher가 생산한 메시지를 메시지 큐에 저장하고, 저장된 데이터를 consumer가 가져갈 수 있도록 "중간 다리 역할"을 해주는 브로커입니다. pub/sub 구조라고 하며 consumer가 데이터를 가져가면 큐에서 데이터가 빠르게 삭제됩니다. - 이벤트 브로커
이벤트 브로커는 메시지 브로커의 기능 + 알파로 이해하시면 됩니다. 세세하게 공부하면 동작과정이 많이 다른데 중요한 점은 이벤트 브로커는 publisher가 생산한 이벤트를 저장하여, 후에 consumer가 특정 시점부터 이벤트를 다시 consume 할 수 있는 장점이 있습니다. (장애가 일어난 시점부터 그 이후의 이벤트들을 다시 처리하는것이 가능) 또한, 대용량 데이터 처리가 가능합니다.
# 메세지 큐의 장점
- 비동조 (Decoupling) : 애플리케이션과 분리
- 탄력성 (Resilience) : 일부가 실패 시 전체에 영향을 받지 않음
- 과잉 (Redundancy) : 실패할 경우 재실행 가능
- 보증 (Guarantees) : 작업이 처리된 걸 확인 가능
- 확장성 (Scalable) : 다수의 프로세스들이 큐에 메시지를 보낼 수 있음
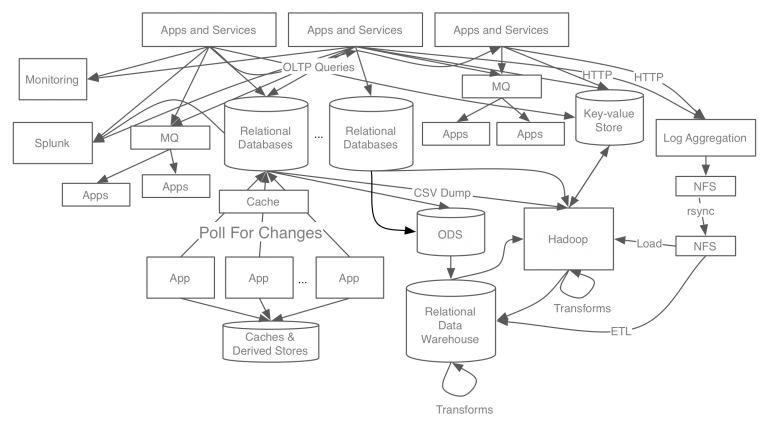
# kafka의 구성 및 동작
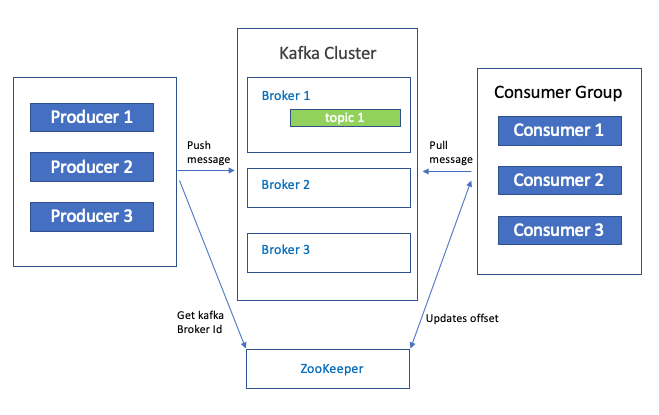
1. broker : kafka cluster는 kafka server들로 이루어져있고 이를 broker라 합니다.
2. topic : producer가 전달한 메세지가 저장되며 메세지 카테고리라고 보면 됩니다.
3. partition(append-only) : topic은 여러 partition을 가지면서 병렬처리와 분산처리가 가능, producer는 round-robin이나 key로 파티션을 선택, 한개의 partition은 consumer group의 하나의 consumer에만 연결 가능
4. zookeeper : kafka cluster에서 분산 메세지 큐의 정보를 관리
5. AMPQ protocol을 사용하지 않고 TCP/IP통신을 통해 바로 디스크로 씁니다.
6. 데이터의 영속성(Persistence)가 보장
# RabbitMQ 구성 및 동작
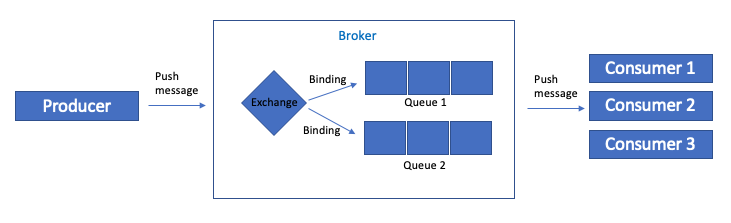
1. AMPQ protocol (advanced message queueing protocol)을 사용합니다.
2. producer가 broker에게 message를 전달하면 broker가 consumer에게 전달하는 구조 (pull이 아님)
3. 수신한 메세지에 알고리즘을 적용해서 어떤 queue에 담을지 결정
# 왜 Kafka를 많이 사용하는가?
결정적으로 성능이 좋다고 널리 알려져있기 때문입니다. 왜 성능이 좋을까요?
- OS 페이지 캐시 - 파티션에 대한 파일 I/O가 메모리에서 처리되어서 빠름
- 브로커는 매핑관리만하고 메세지 필터, 재전송은 프로듀서, 컨슈머가 처리
- 묶어서 보내기, 묶어서 받기 - 전체적인 처리량이 늘어남
- 파티션/컨슈머 추가로 수평확장 용이
- 리플리카 - 파티션의 복제본이 각 브로커에 생김
# 그럼에도 RabbitMQ를 선택하게된 이유
Kafka는 대용량 처리가 가능한만큼 굉장한 리소스를 잡아먹기 때문에 aws를 사용했을때 큰 유지비가 듭니다. 개발하려는 프로젝트가 전국민을 대상으로하는 서비스이긴 하지만 사실 사용자는 거의 개발자들밖에 없을것으로 예상되어 굳이 대용량 처리를 하는 kafka를 쓰지않아도 되겠다라고 판단했습니다. rabbitMQ로도 저희가 구현하려는 서비스를 충분히 제공할 수 있고 비용도 절약될 것입니다.
# References
https://yarisong.tistory.com/62
https://willseungh0.tistory.com/32
https://velog.io/@qlgks1/%EC%B9%B4%ED%94%84%EC%B9%B4Kafka%EB%9E%80
https://escapefromcoding.tistory.com/705
https://www.youtube.com/watch?v=0Ssx7jJJADI&ab_channel=%EC%B5%9C%EB%B2%94%EA%B7%A0
'Back-end > 특공대 project' 카테고리의 다른 글
| DDD의 꽃 Aggregate 설계 (0) | 2023.09.27 |
|---|