
이 글은 DDD 설계 단계 중 EventStorming을 마친 후, aggregate 추출 단계만을 위한 글입니다.
프로젝트 설계 방식을 DDD로 한번 해보자라는 다짐으로 조금조금씩 블로그 글들을 따라 해보았는데 전략적 설계에 Aggregate 추출 단계에서 굉장한 어려움을 겪었습니다. aggregate, 트랜잭션, 일관성, 낙관적 락 등 설계에 필요한 개념들과 제 프로젝트에는 어떻게 적용시켰는지 알아보겠습니다.
# Aggregate란 무엇인가?
서로 관련이 있는 도메인 모델들의 집합이며 Aggregate Root, Entity, VO로 이루어져 있습니다. 여기서 외부 객체는 Aggregate Root를 통해서만 해당 aggregate에 접근할 수 있습니다.
# Aggregate는 왜 필요한가?
1. 일관성 유지
Aggregate는 일관성이 유지되어야 하는 연관된 객체와 행위의 집합을 나타냅니다.
2. 트랜잭션 관리
하나의 트랜잭션은 하나의 aggregate만 수정하도록 하여 데이터의 일관성, 무결성을 보장해줍니다.
# 트랜잭션이란 무엇인가?
데이터베이스의 상태를 변화시키기 해서 수행하는 작업의 단위
하나의 쿼리나 DML이 아니라 어떤 기능을 위한 쿼리의 묶음이라고 보면 됩니다.
# 트랜잭션의 특징 ACID
1. 원자성 (atomicity)
트랜잭션이 데이터베이스에 모두 반영되던가, 아니면 전혀 반영되지 않아야 합니다. (commit 실패 시 rollback)
2. 일관성 (consistency)
트랜잭션이 진행되는 동안에 데이터베이스가 변경되더라도 업데이트된 데이터베이스로 트랜잭션이 진행되는 것이 아니라, 처음에 트랜잭션을 진행하기 위해 참조한 데이터베이스로 진행됩니다.
하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 합니다.
Q. 실시간으로 업데이트된 데이터베이스로 트랜잭션이 적용되어야 하는 것 아닌가요? 트랜잭션이 동시에 동작하면 일관성이 파괴되잖아요.
A. 이 문제는 3번 고립성이 보장되면 자동으로 해결되는 문제입니다.
3. 고립성 (Isolation)
어떤 하나의 트랜잭션이라도, 다른 트랜잭션의 연산에 끼어들 수 없습니다.
4. 지속성 (Durability)
트랜잭션이 성공적으로 완료됐을 경우, 결과는 영구적으로 반영되어야 합니다.
이것 말고도 여러 트랜잭션을 동시에 안전하게 실행해야 하는 동시성 문제도 존재합니다. 해결책으로 낙관적 락, 비관적 락, 직렬화 등이 있는데 자세한 건 링크를 보시고 이해하시면 됩니다. https://hwannny.tistory.com/81
# Aggregate 직접 설계하기
그럼 위의 내용을 토대로 제 프로젝트의 aggregate를 한번 설계해 보도록 하겠습니다. 서비스에 대해서 자세히 서술하진 않겠지만 그냥 일반적인 사용자, 거래글, 채팅 서비스를 제공하려 한다고만 아시면 됩니다.
1. 사용자와 공간(거래글)
- 사용자 애그리거트 내에 포함
- 공간 애그리거트 내에 포함
- 별도의 애그리거트로 분리
1. 사용자가 공간을 수정할 수 있으므로 별도의 에그리거트는 안되지 않나?
사용자를 사람으로 보면 안 됩니다. 애그리거트 내에 하나의 객체로 봐야 합니다. "서비스상에서 사용자가 공간을 생성한다"가 아니라 사용자라는 애그리거트에서 변경사항이 생겼을 때 그 변경사항이 공간 에그리거트에도 영향을 미치냐를 봐야 합니다.
2. 그렇다면 사용자와 공간은 서로 직접적인 수정이 일어날 수 있는가?
사용자가 늘어난다고 해서 공간이 늘어나지 않고 공간이 늘어난다고 해서 사용자가 늘지 않습니다. 서로 독립적이라 할 수 있고 따라서 둘은 별도의 aggregate라 볼 수 있습니다.
3. 별도의 에그리거트일 때와 하나로 묶었을 때의 장단점은 무엇인가?
별도의 에그리거트로 관리
- 장점 - 병렬 처리와 확장성, 변경의 영향을 최소화
- 단점 - 높은 시스템 복잡도
한 에그리거트에서 관리
- 장점 - 트랜잭션 관리 간소화, 일관성 유지
- 단점 - 확장성의 제한, 변경의 영향범위가 넓어짐
실선은 직접참조, 점선은 간접참조를 의미합니다.
직접참조는 예를 들어, 사용자 aggregate안에 사용자, 거주지라는 도메인이 있을 때 사용자 entity안에 거주지가 그대로 포함되는 형태입니다. 간접 참조는 식별자나 키만 사용하여 간접적으로 참조하는 형태입니다.
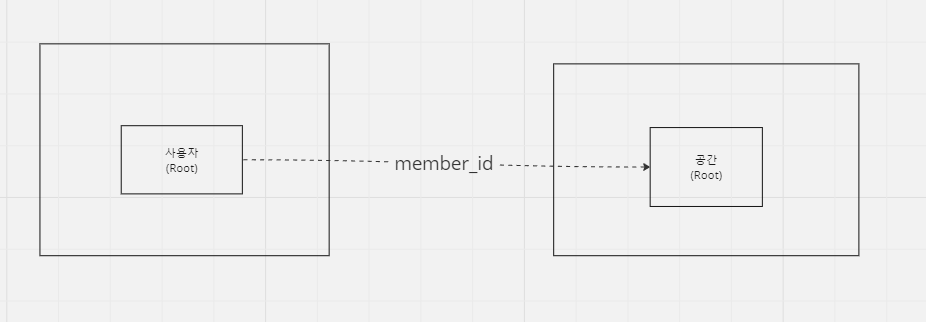
2. 사용자와 공간, 관심공간
- 사용자 애그리거트 내에 포함
- 공간 애그리거트 내에 포함
- 별도의 애그리거트로 분리
1. 관심공간 별도의 기능이 있는가?
별도의 기능이 많다면 별도의 aggregate로 따로 관리하는 게 가장 좋다고 합니다. 하지만 사실 우리는 관심 공간에 대한 특별한 기능이 없어서 어디에 포함시키는 게 좀 더 개발에 간편할 것이라 판단했습니다.
2. 1, 3번 중에 어디가 좋은가?
결론부터 말하면 이것도 크게 상관이 없습니다.
사용자의 삭제 → 관심 공간의 삭제
공간의 삭제 → 관심 공간의 삭제
결국 사용자, 공간, 관심공간을 하나의 aggregate로 묶지 않는 이상 하나의 aggregate에만 영향을 주는 것은 불가능합니다.
이 문제에 대해서 굉장히 많이 헤맸습니다. aggregate의 원칙은 지키고 싶었으나 어떤 방법으로 하든 지킬 수 없는 상황이 있었고 이를 해결할만한 aggregate 구조가 있는데 발상을 못한 건지, 아니면 원칙을 100% 지키는 것은 애초에 불가능한 건지 알 수가 없었습니다.
수많은 공부 후에 깨달은 것은 저희가 하나의 트랜잭션으로 원칙을 100% 지키려 했던 것이 문제였습니다. 이게 무슨 의미냐하면, 두 애그리거트에 수정을 발생시키는 트랜잭션 하나를 각각의 애그리거트에서 동작하는 트랜잭션 2개로 나눌 수 있는 방법이 있습니다. 어떤 트랜잭션이 수행될 때 이벤트라는 것을 다른 애그리거트에 전달해서 비동기적으로 다른 애그리거트에서 따로 트랜잭션을 수행하면 됩니다.
따라서 결론은 사용자든, 공간이든 어떤 aggregate에 포함되어도 된다는 것이고 다만, 서비스 비즈니스 로직을 고려했을 때 응집력 커지는 곳이나 한 애그리거트 내에 불변식이 유지되는 곳에 넣는 것이 좋습니다.
이 프로젝트에는 어디에 포함되든 차이가 없어서 사용자 aggregate에 넣었습니다.
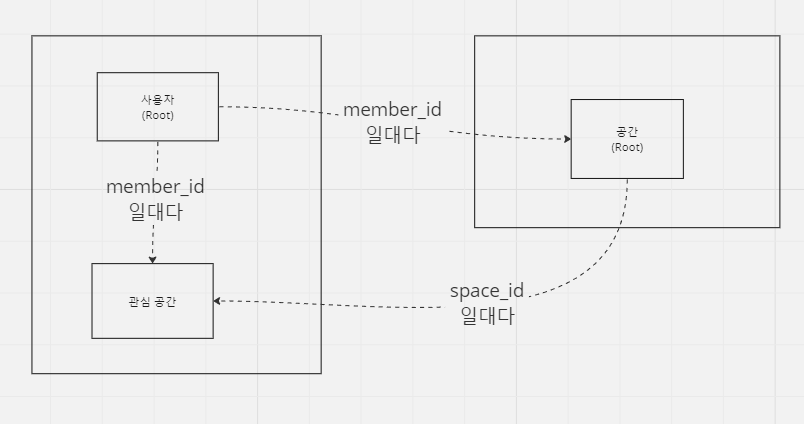
3. 채팅방과 공간
- 공간 애그리거트 내에 포함
- 별도의 애그리거트로 분리
1. life cycle이 유사한가?
채팅방은 공간이 없다면 생성될 수 없습니다.
하지만 둘의 삭제는 독립적이고 기능이 서로 의존적인 느낌은 없어서 1, 2 둘 다 가능한 것 같고 2번을 택했습니다.
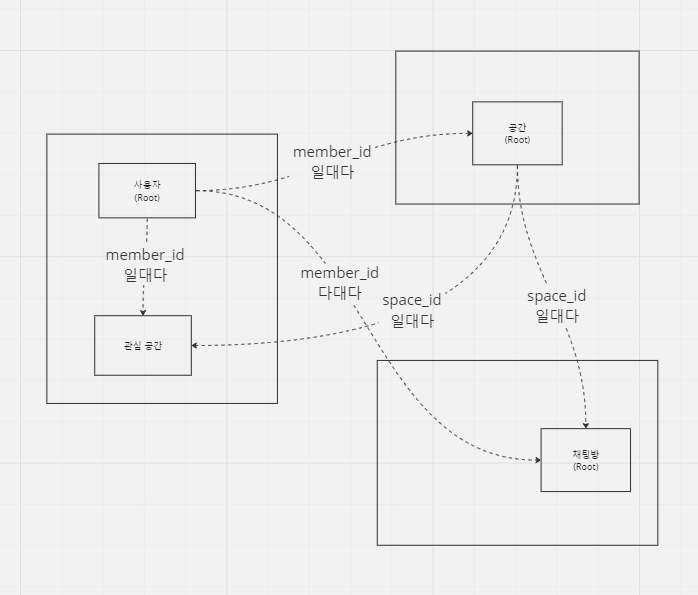
4. 채팅방과 채팅 메시지
- 채팅 애그리거트 내에 포함
- 별도의 애그리거트로 분리
1. life cycle이 유사한가?
채팅 메시지는 채팅방이 있어야만 존재합니다.
채팅방이 사라지면 채팅 메시지가 사라집니다.
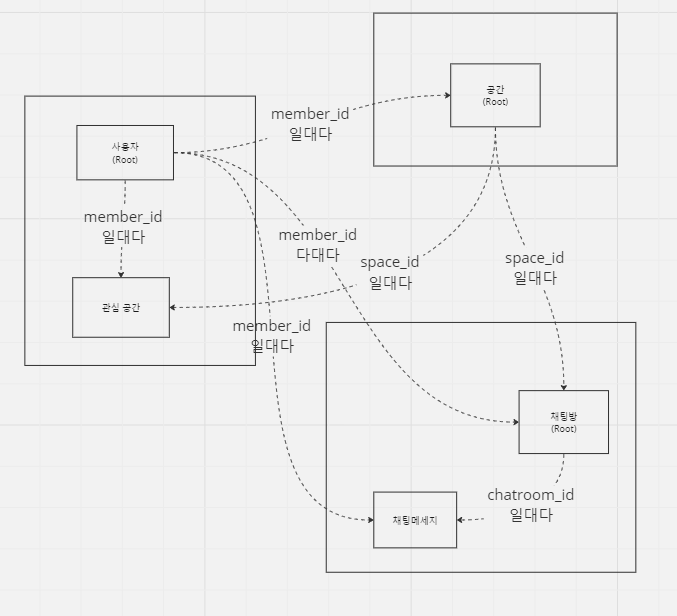
5. 후기와 공간
- 공간 애그리거트 내에 포함
- 사용자 애그리거트 내에 포함
- 별도의 애그리거트로 분리
1. life cycle이 유사한가?
사용자 삭제 → 후기 삭제
공간 삭제 → 후기 삭제
공간 쪽 데이터와 더 일관성이 필요해 보여서 공간에 포함시켰습니다.
DB는 대충 이런 느낌으로 나타낼 수 있습니다.
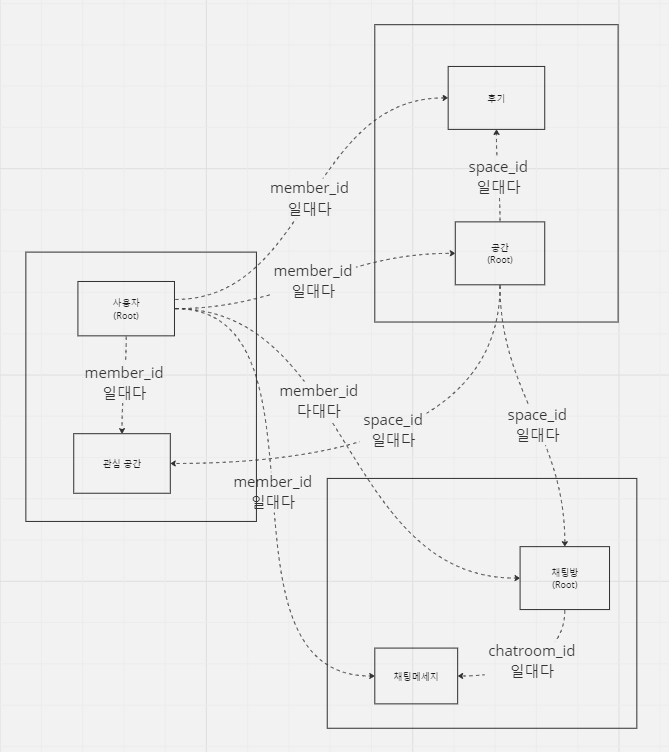

제 결론은 "aggregate 설계의 정답은 없다"입니다. 어떤 로직을 가지는지, 어떤 툴들을 쓰고 관리는 어떤 방식으로 할지, 추후에 추가될만한 기능은 어떤 것들이 있을지, 트랜잭션은 어떻게 관리할지 등 미리 내다보아야 할 것들이 너무나도 많습니다. 물론 설계를 오래 해오시고 전문가의 영역이신 분들은 뚝딱뚝딱 만들어서 최선의 해결책을 도출해 낼 것이란 생각은 듭니다만 그분들은 지금 제 글을 읽지도 않겠죠... 일단은 자신만의 타당한 근거로 설계를 하고 추후에 충분히 바뀔 수 있다는 점을 염두에 두고 설계를 해야 할 듯합니다.
# References
https://be-developer.tistory.com/110
https://hwannny.tistory.com/81
chatgpt
'Back-end > 특공대 project' 카테고리의 다른 글
| 메세지 큐, 그리고 Kafka vs RabbitMQ (1) | 2023.09.06 |
|---|